Dense Sparsity
The main idea of Inception is creating a method for obtaining a level of sparsity within the functional blocks of dense matrices. As mentioned before, this is motivated by the current hardwares affinity to dense matrices. Thus the goal is to find the optimal local block which can be used in a dense configuration and repeat it spatially.
As suggested by Arora et al. in [2] they suggest a layer by layer construction based on correlation statistics from the output of the layers. These “Inception” modules are stacked on top of each other. In order to avoid patch alignment issues, the current instance is limited to 1x1, 3x3, and 5x5 convolutions. A liberal use of 1x1 convolutions are used in order to reduce the complexity that would be incurred by the 5x5 convolutions. The paper states that even a modest amount of 5x5 convolutions can be prohibitively expensive. You can see in figure 2 how they used 1x1 convolutions to reduce the dimensions in hopes of capturing the most amount of information in the lowest dimension embedding. The 1x1 convolutions are dual purpose as they also include the ReLu nonlinearity.
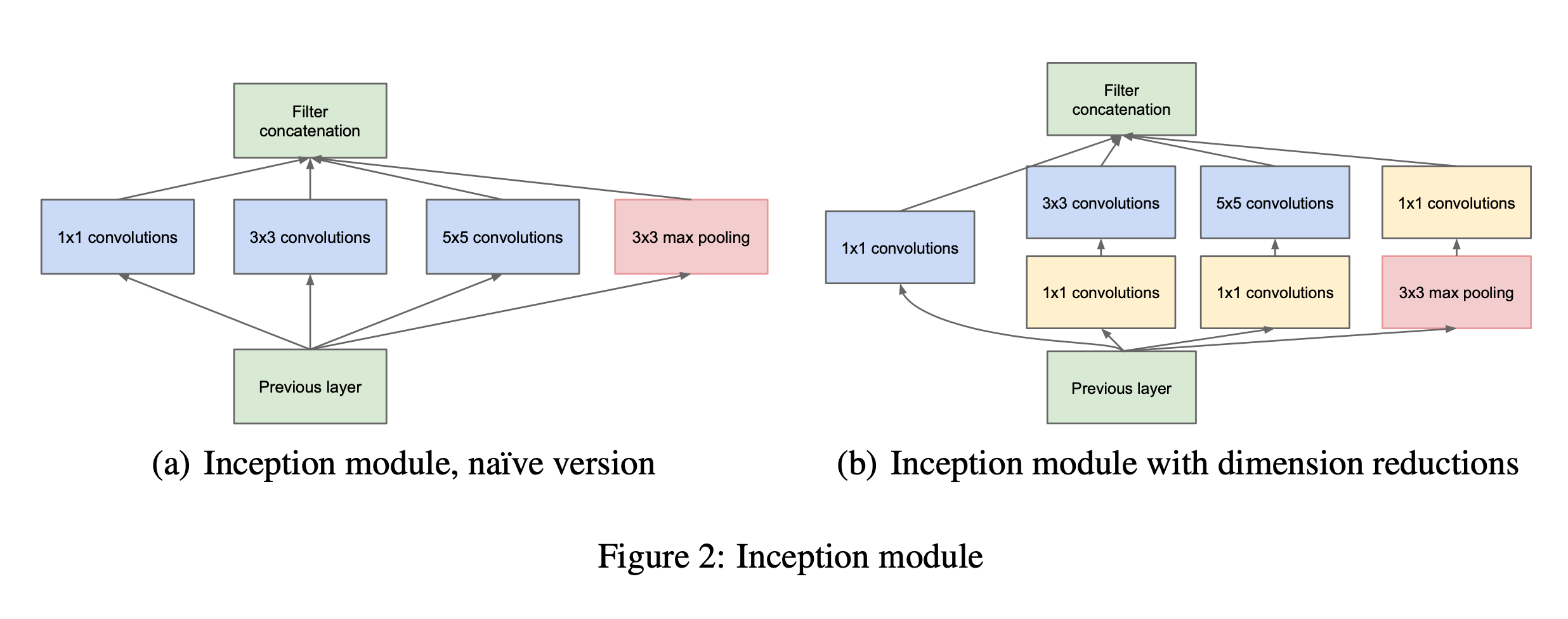
Inception networks are typically built with the module above, and it was found to be better to only use inception models at the higher layers, while lower layers remain standard convolution.
The main benefits of inception is the ability to create larger networks with computationally realistic budgets, but the drawback is the manual construction which is needed in order to make that happen.
[2] Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013.