Per Section Breakdown
5.1 Matrix Multiplication
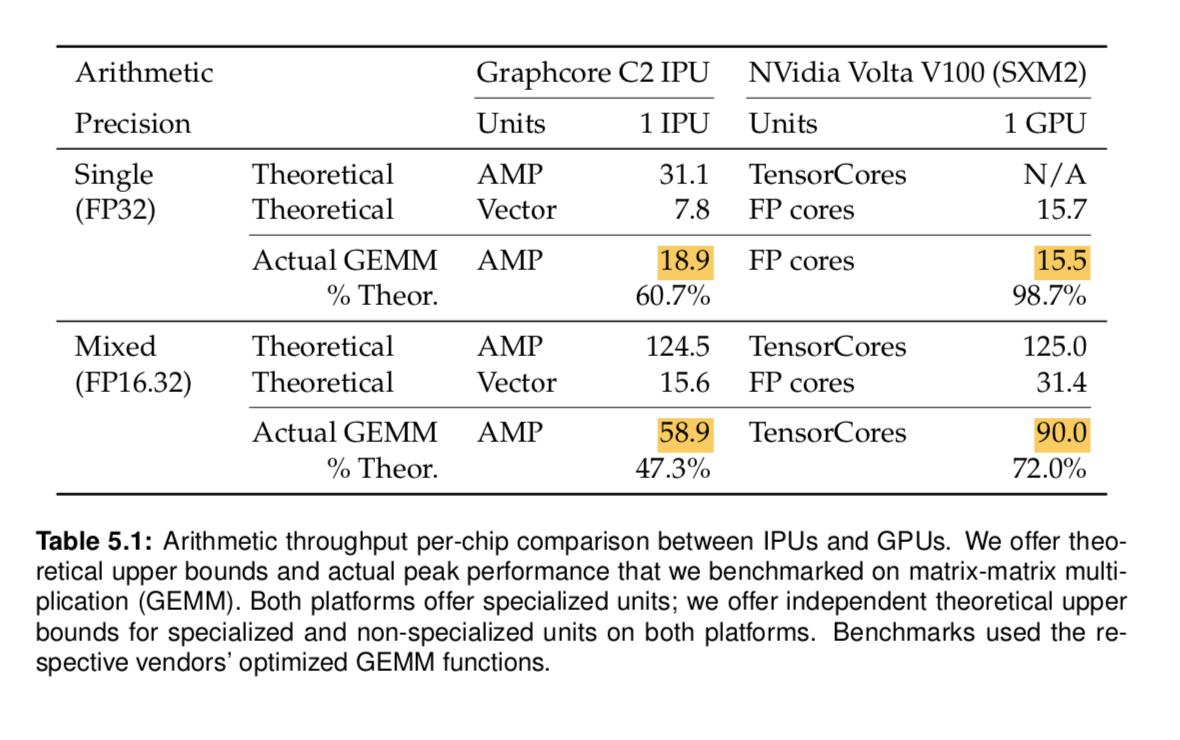
Matmul is a popular proxy for chip performance. In single precision, IPU is clear winner, but in mixed precision, the comparison does not yield a clear winner.
Each major chip has specialized hardware to create speedups for the heavily used operations. Accumulating Matrix Product (AMP) is the IPU hardware to accelerate matrix computations, similar to GPU’s TensorCore.
5.2 Convolution
The convolution provides interesting discussion, exposing the IPUs preference for smaller batch sizes (due to memory limits) while at the same time, the GPU is limited because it doesn’t start to utilize resources efficiently until batch sizes reach 512+. For instance, the ResNeXt architecture sees speedups of 700x due to lack of consideration for GPU efficiency.
5.3 PRNG
The Pseudo-Random Number generation hardware (PRNG) is created on dedicated, in-core PRNG hardware yielding 4.9x more aggregate throughput than the V100, it generates lower quality of randomness in comparison.