Latency
Latency is quite simple on local memory, which is a key advantage to the system. All tiles reading a value from its local memory is 6 clock cycles regardless of loading and independent of other tiles. This is consistent and explained by the Architecture.
Bandwidth
Read Bandwidth
The theoretical bandwidth is 31.1 TB/s, which is the product of each tiles read of 16 bytes per clock, with CLK = 1.6GHz and the tile count of 1,216.
Table 3.1 shows the best summary of results. Its important to note that practical user bandwidth, programming without any optimization, should expect to see a quarter of the theoretical limit: 7.59GB/s.
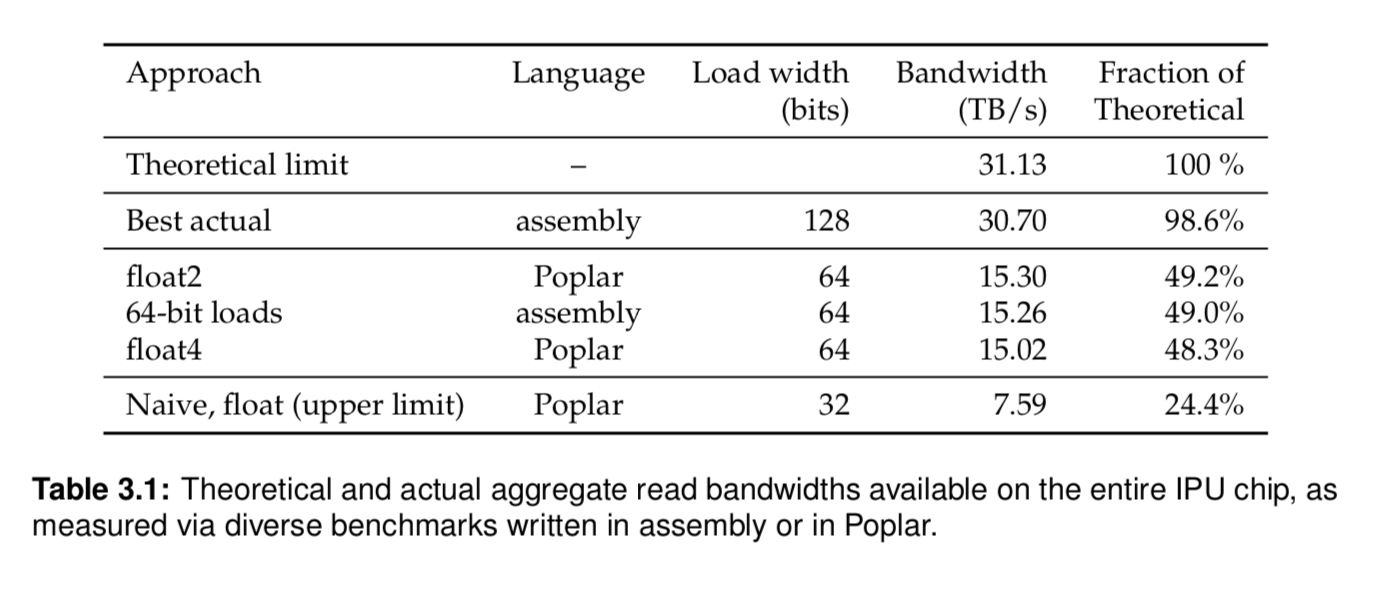
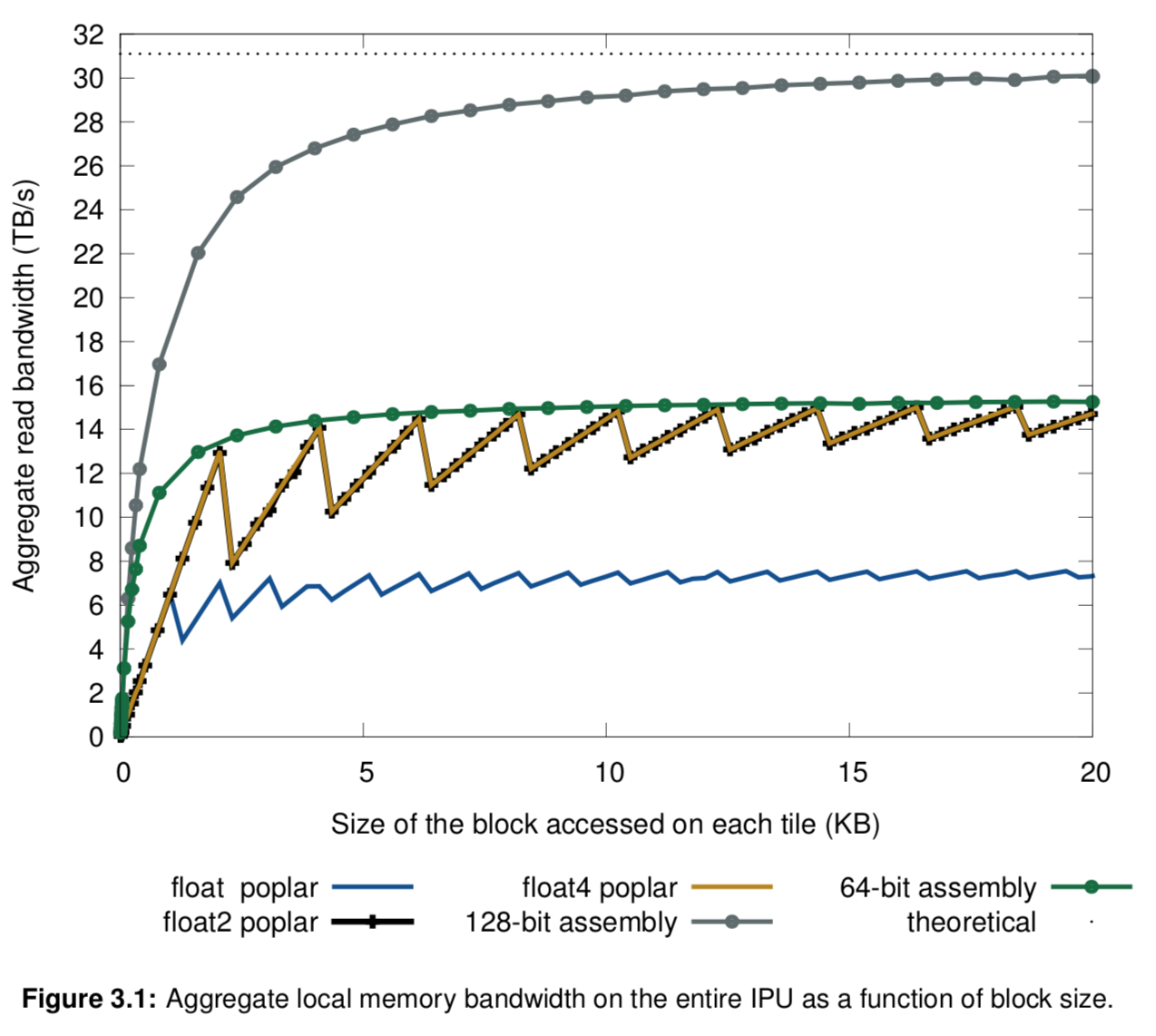
The size of block accessed also affect performance. As a rule of thumb, any accesses greater than 8KB return >95% of theoretical performance.
Figure 3.1 shows this:
Write Bandwidth
Writing can achieve the full theoretical bandwidth. Each tile is spec’ed to write 8 bytes per clock cycle (half of read’s 16 bytes/clk). Thus 15.5 TB/s is the expected write bandwidth.