This is a bit of a departure from the regular, today I looked at some fundamentals of search
From Google Cluster
Query execution consists of two major phases. In the first phase, the index servers consult an inverted index that maps each query word to a matching list of documents (the hit list). The index servers then determine a set of relevant documents by intersecting the hit lists of the individual query words, and they compute a relevance score for each document. This relevance score determines the order of results on the output page.
The search process is challenging because of the large amount of data: The raw documents comprise several tens of terabytes of uncompressed data, and the inverted index resulting from this raw data is itself many terabytes of data. Fortunately, the search is highly parallelizable by dividing the index into pieces (index shards), each having a randomly chosen subset of documents from the full index. A pool of machines serves requests for each shard, and the overall index cluster contains one pool for each shard.
The final result of this first phase of query execution is an ordered list of document identifiers (docids).
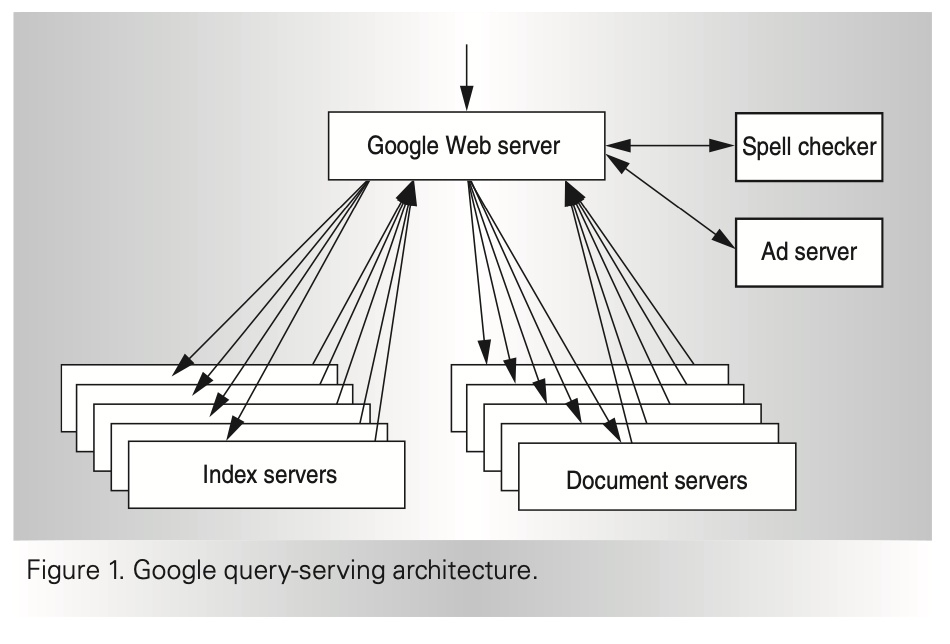
As Figure 1 shows, the second phase involves taking this list of docids and computing the actual title and uniform resource locator of these documents, along with a query-specific document summary.
A lot of the document talks about price/performance characteristics that the team traded off to have the most efficient setup. All their focus is performance/$ without getting distracted on any other metric. Their description of the search problem is reassuring because that is effectively how I envision it. It is a two step process, generating the index, and then ranking hits from that index. I think there is a potential for BERT to help with the index, so the full system is auto-indexed or learned instead of trying to hand craft it.
From The Anatomy of a Large-Scale Hypertextual Web Search Engine
The web creates new challenges for information retrieval.
The paper introduces the web in contrast to hand curated search engines like Yahoo! as it explains how the technique and scale of the design works. Google was chosen as a name because it is a common spelling of googol, or , inspired by the scale at which they aspire to work.
My aim from this paper is to understand the mechanics of search, and what system pieces are required to make an engine that can serve relevant information. They predict that the web may be an index of a billion documents in 2000. The problem Google solved in 2000 may be similar to the problems today we may be solving at company-wide levels.
I want to keep an eye on the differences that Google faced with the web versus what problems I may run into by indexing a known corpus for search-ability. The web is itself very dynamic. Additions to the graph arrive exponentially.
At scale, they note the balance between a growing internet and the growth of the technology that supports it. Hardware does grow while the internet also grows, but there are notable lagging technologies that slow the direct application of improved hardware: disk seek time is a notable one, and one I believe we still must deal with today.
Quality Matters because people are only able to view a limited number of documents, though the corpus is massive. This human limitation will not change. The paper notes: This very high precision is important even at the expense of recall.
First Key Feature using link information to aid in high precision results. This is PageRank. It uses knowledge of the links between sites to aid in the recommendation of sites. Some form of this I believe must still be used today at Google. If interested, the web is full of information on PageRank, so I’ll pass over it.
Second Key Feature Anchor text is the placeholder text to show a user instead of the link. This is done via the anchor tag in html <a href = 'http://www.somesite.com'>This is my anchor text</a>. Google exploits this for further information about relevance. The paper also notes of other features, such as location information.
Architecture Overview
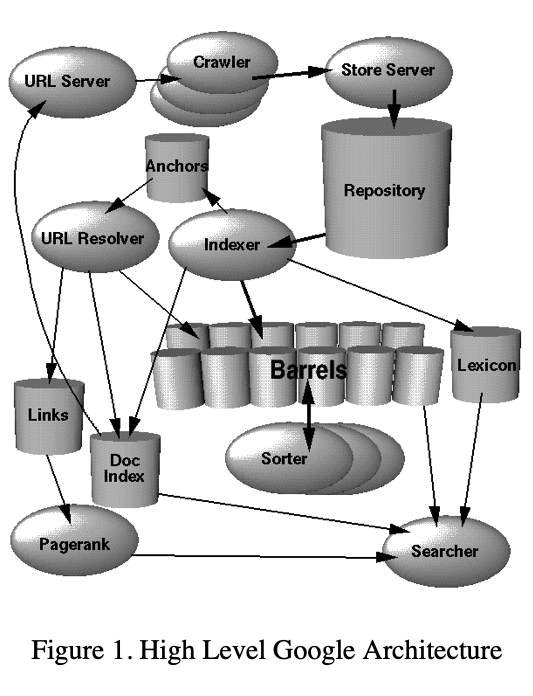
The text of this page is worth pasting directly:
The indexing function is performed by the indexer and the sorter. The indexer performs a number of functions. It reads the repository, uncompresses the documents, and parses them. Each document is converted into a set of word occurrences called hits. The hits record the word, position in document, an approximation of font size, and capitalization. The indexer distributes these hits into a set of “barrels”, creating a partially sorted forward index.
The indexer performs another important function. It parses out all the links in every web page and stores important information about them in an anchors file. This file contains enough information to determine where each link points from and to, and the text of the link.
The URLresolver reads the anchors file and converts relative URLs into absolute URLs and in turn into docIDs. It puts the anchor text into the forward index, associated with the docID that the anchor points to. It also generates a database of links which are pairs of docIDs. The links database is used to compute PageRanks for all the documents.
The sorter takes the barrels, which are sorted by docID (this is a simplification, see Section 4.2.5), and resorts them by wordID to generate the inverted index. A program called DumpLexicon takes this list together with the lexicon produced by the indexer and generates a new lexicon to be used by the searcher. The searcher is run by a web server and uses the lexicon built by DumpLexicon together with the inverted index and the PageRanks to answer queries.
Hit Lists The documents that contain the keys to hit words are a heavy aspect of the system requiring much storage. By using bit level encoding, Google minimizes the impact of this storage requirement.
Figure 3 shows the smashing of information into bits for this usecase:
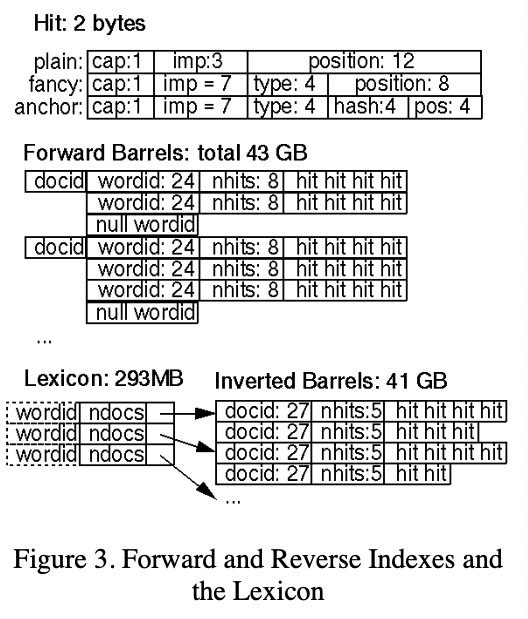
The practicality of this paper is cool. Often the describe design problems and why they made a particular design choice. They decided to keep two copies of the inverted index based on separate use-cases: single vs multi-word queries.
Social implications the web crawler is a fascinating piece of the puzzle and includes humorous anecdotes of webmasters’ first interaction with the Google Crawler, and angry people trying to avoid the crawler.
This section was key to my understanding:
Indexing Documents into Barrels – After each document is parsed, it is encoded into a number of barrels. Every word is converted into a wordID by using an in-memory hash table – the lexicon. New additions to the lexicon hash table are logged to a file. Once the words are converted into wordID’s, their occurrences in the current document are translated into hit lists and are written into the forward barrels. The main difficulty with parallelization of the indexing phase is that the lexicon needs to be shared. Instead of sharing the lexicon, we took the approach of writing a log of all the extra words that were not in a base lexicon, which we fixed at 14 million words. That way multiple indexers can run in parallel and then the small log file of extra words can be processed by one final indexer.
Sorting -- In order to generate the inverted index, the sorter takes each of the forward barrels and sorts it by wordID to produce an inverted barrel for title and anchor hits and a full text inverted barrel. This process happens one barrel at a time, thus requiring little temporary storage. Also, we parallelize the sorting phase to use as many machines as we have simply by running multiple sorters, which can process different buckets at the same time. Since the barrels don’t fit into main memory, the sorter further subdivides them into baskets which do fit into memory based on wordID and docID. Then the sorter, loads each basket into memory, sorts it and writes its contents into the short inverted barrel and the full inverted barrel.
The biggest problem facing users of web search engines today is the quality of the results they get back.
I think to hand spin any search engine, it is imperative to focus on precision foremost.