Introduction
Recurrent Neural networks, LSTM’s and GRU’s have been typical model choices for the state of the art in sequence to sequence translation. This paper proposes a using exclusively the attention mechanism that was previously played only a part in the greater network. While retaining the classic encoder-decoder architecture, they leverage the attention mechanism to full effect.
One immediate benefit of using exclusively attention is the alleviation of the sequential bottleneck inherent in the past recurrent network structure.
Background
Many groups have worked towards reducing the sequential computation bottleneck, such as the Extended Neural GPU, ByteNet, and ConvS2S, all which use CNN’s as their basic building block. However, these methods of computing hidden representations in parallel all paid either a linear or logarithmic complexity to learn distant relationships between positions. The transformer has reduced this cost to effectively linear. There are some caveats being the loss of resolution in the averaging attention-weighted positions, which they counteract with Multi-Head Attention.
Self Attention or ‘intra-attention’ in an attention mechanism used successfully in the past. It is a process of codifying the relationships relating different positions of a single sequence into a single representation.
Model Architecture
At the highest level, the architecture is split into an encoder-decoder scheme. The left is the encoder, while the right is the decoder as seen in figure 1.
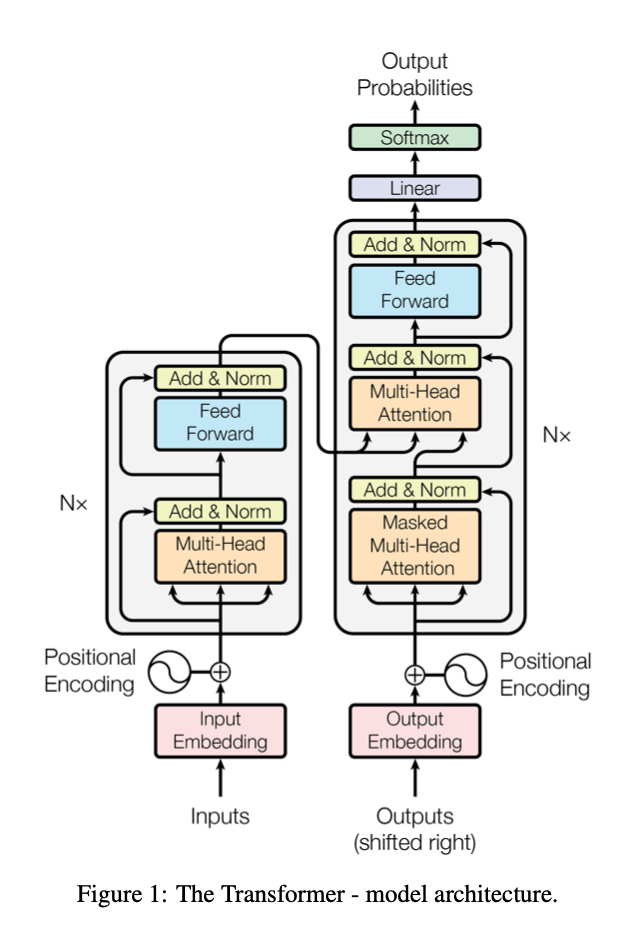
Encoder The encoder is composed of 6 identically stacked encoding layers build from two fundamental sublayers. The first is the Multi-Head Attention layer, which feeds into a fully connected feed-forward network. There is a residual connection for each sublayer, and for simplicity, all layers produce output dimensions of 512.
Decoder The decoding layers also employ a stack of 6 identical layers. The decoder has an additional Multi-Head Attention mechanism that is fed by the output of the encoder. The paper also describes a mechanism to make sure the decode layer is never attending to positions beyond the current .