The TextRank paper publishes results on keyword extraction and sentence extraction. Keyword extraction is the process of pulling keywords out of an abstract (from a paper) to help with search terms.
This is a short summary of the TextRank method for keyword extraction:
Keyword Extraction
Prior Work: This paper (written in 2004) is not able to compare to modern state of the art; however, they identify prior ways of achieving keyword extraction. Firstly, and quite simply, you could look at word frequency; however, this method is generally found to have poor results. They mention previous state of the art is represented by supervised learning method. This method, including linguistic knowledge (such as parts of speech) almost doubled previous best accuracy. Quite compelling.
TextRank for Keyword Extraction: In order to use TextRank, you must first build the word graph. This paper chose to filter nodes based on semantic meaning, and found that nouns and adjectives perform the best. After filtering the nodes, they generate connections (edges of the graph) by using a co-occuring window of words (set between 2 and 10). Figure 2 shows a example of this graph:
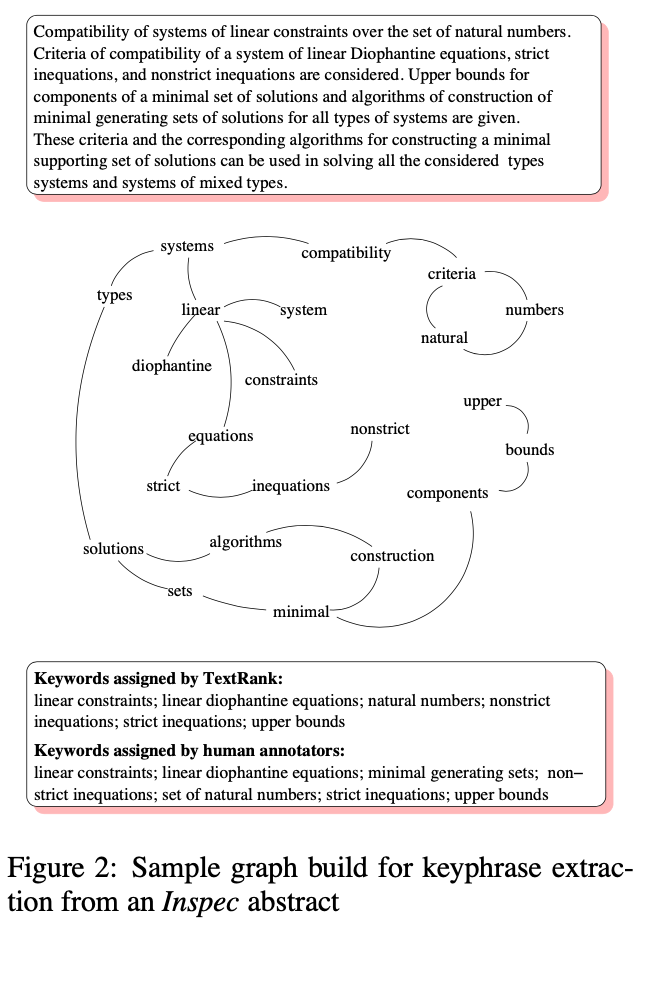
After computing the graph, the ranking algorithm is iteratively run usually for 20-30 iterations. Once the vertex scores are computed, they are shown in reverse sorted order to show the highest ranking vertices first.
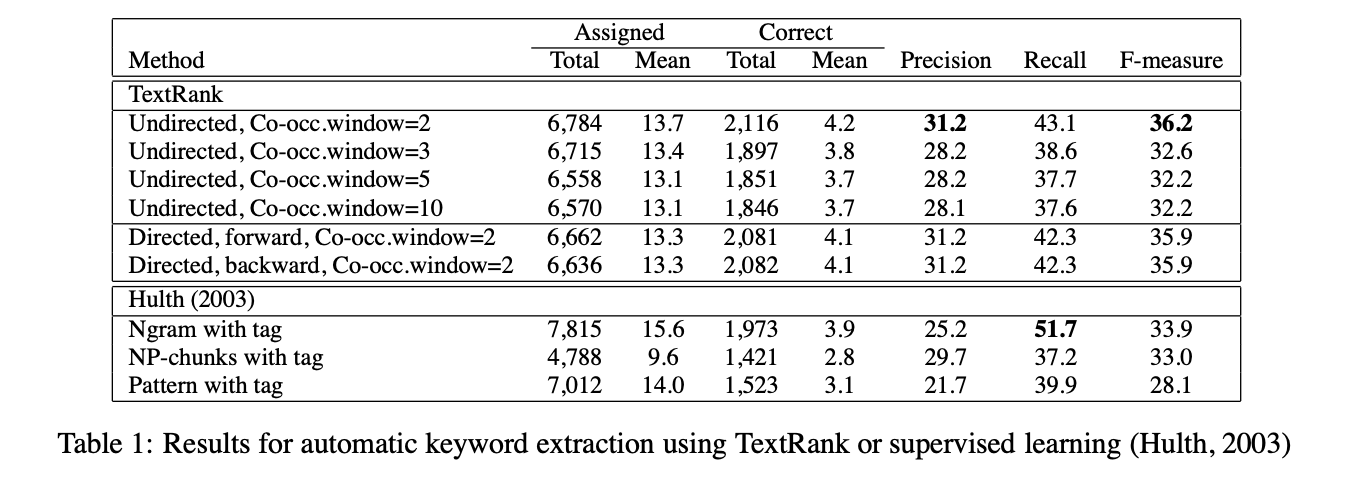
Evaluation: Table one summarizes their results: posting state of the art results in Precision and F-measure, but not surpassing Hulth’s recall score.