The paper looks at 6 datasets and runs experiments on them to show the general positive effect of dropout on all of them. The results are quite compelling.
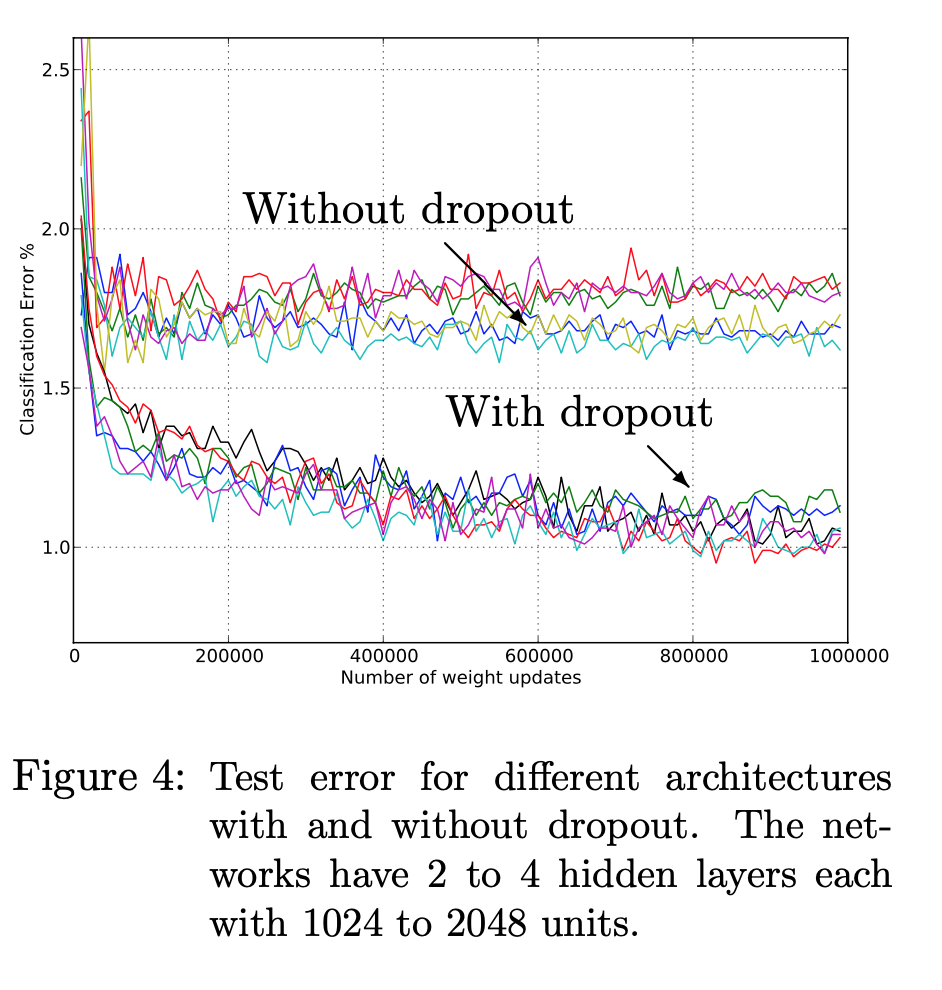
MNIST They ran multiple architectures with frozen hyperparameters to see the difference that dropout provides, and it is clear with the clustering that dropout provides performance advantages:
SVHN that is, Street View House Numbers. They note the additional gains by adding dropout to the CNN layers, though the number of parameters are still small, it provides noise to the fully connected layers which results in better generalization. The gain was from 3.02% to 2.55%.
CIFAR 10/100 The paper shows increases in the vision task of Cifar, where the greatest error posted to date for CIFAR 100 uses dropout (where another technique was SOTA in Cifar 10).
ImageNet The main takeaway from the ImageNet results is the staggering difference in the 2012 competition results that dropout seems to provide. Other teams posted top-5 test error of 26% while the dropout net resulted in only 16%.
TIMIT a clean speech dataset. The paper shows dropout improving results of 20.5% to 19.7%. However, this is an entirely separate AI task from vision.
Reuters-RCV1 a text dataset. They show improvement over best networks without dropout by 1.5% from 30%. Not quite as good as improvements in vision and speech but improvements nonetheless.
RNA a dataset which has been a good suit for Bayesian Networks, due to the advantage of the prior and lack of massive amounts of data. The authors were interested to see how dropout would perform in cases where Bayesian were previously successful. The table of results shows that Bayesian networks are still superior; however, dropout significantly improves upon the neural network best results.
Comparisons against other Regularizers Dropout is a method to prevent overfitting, ie a regularizer. Thus the authors compare results of regularization techniques on MNIST. Results are shown below, with top results being a combination of dropout and max norm.
