Why ResNeXt
I chose ResNeXt because I’ve seen it come up in various state of the art works. I read through the ResNet original paper, but that was before starting this website. Reviewing the original, it is obvious that Kaiming worked on them both, as the two papers are very similar.
Introductions
The paper starts off with the current approach to vision being network engineering to allow the machine to do most of the work. With this network engineering, the paper reviews three latest popular networks: VGG/ResNets, Inception Nets, and ResNeXt.
VGG/ResNets these are effective and simple in their approach of stacking basic building blocks of the same shape. ResNet has inherited this philosophy from VGG. Hyper parameters are filled in by the essential dimension being depth.
Inception Nets are less simple because they utilized specially architected topologies to achieve computational efficiency at the expense of generality. They use a split-merge-transform strategy. Hyper parameter tuning is more difficult due to the non-uniformity.
ResNeXt leverages the building block approach from ResNets, while taking the split-merge-transform strategy from Inception nets. This gives generally an easier time with hyper parameters, while achieving the good computational efficiency of Inception. You can see the block diagram in figure 1.
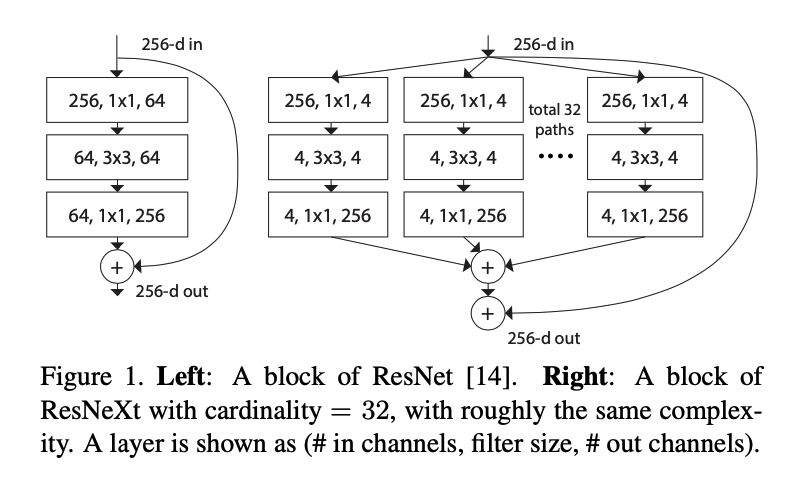
Cardinality
From the split-merge-transform architecture, this paper proposes a new dimension (the NeXt dimension), called cardinality. This is the number of transforms from the S-M-T configuration. As I look at the rest of this paper, I hope to get a better understanding of the concept of cardinality. I’m not as comfortable with the S-M-T technique, so hopefully the paper does not assume full mastery of the technique.