Self-supervised Learning
This type of learning uses less labels, and tries to get the algorithm to simply pattern match by looking at a large sum of images. By using fully supervised techniques that are already off the shelf and popular, it provides some level of understanding of how deeply their colorization algorithm is capturing semantic information.
Their model is akin to an auto-encoder; however, in this case it is a cross channel encoder because it is converting from greyscale to color. The performed two tests to evaluate feature learning.
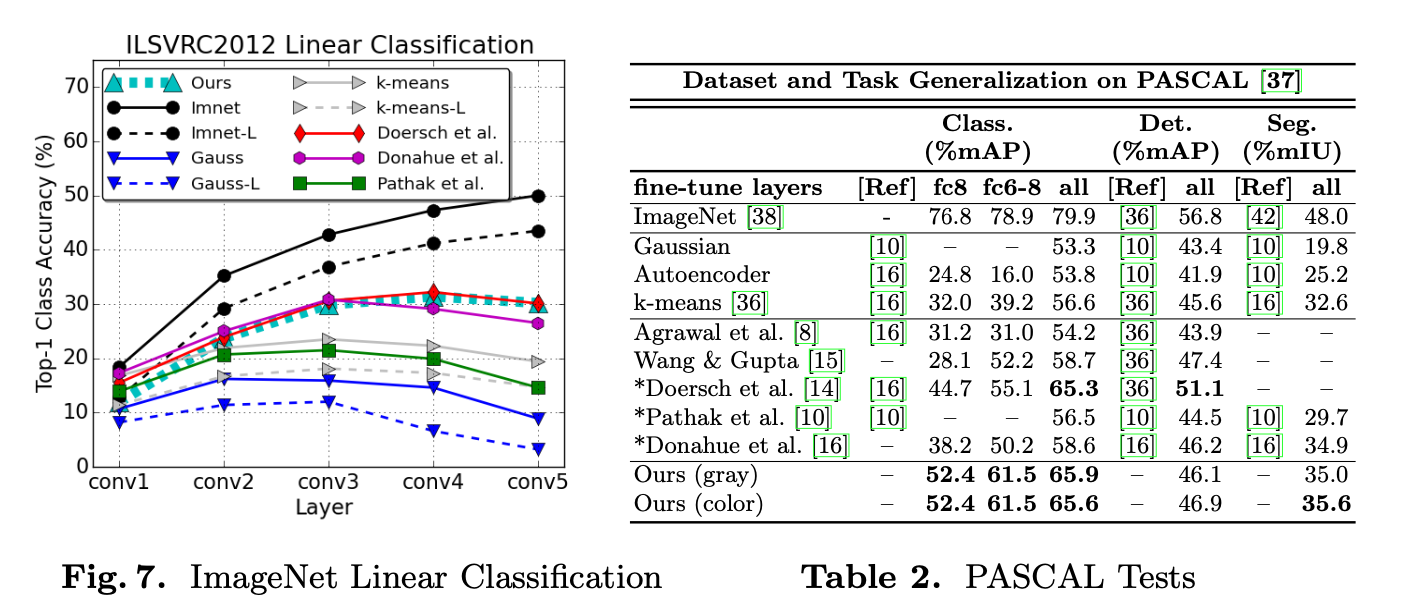
ImageNet Classification They freeze the weights of their model which was trained on ImageNet input images only, and then freeze all layers adding a linear classifier to each convolutional layer. They can then see how the semantic information is captured in their classifier. There is a 6% loss of accuracy, but it is seemingly a constant, and degrades performance to 6% across all three methods. See figure 7.
PASCAL Tests They also ran their model through a triad of tests from the PASCAL dataset. Classification, detection and segmentation. Here they find good results in state of the art performance on self-supervised techniques for segmentation and detection. See table 2.
Conclusion
It looks as though semantic information is well held in colorization techniques. I think that due to the ease of capturing labeled and unlabeled color data (ie converting color images to greyscale), the model archetype could improve semantically held information for all tasks from classification to segmentation. Here are some old real black and white photos colorized by the algorithm.
